Human Rights First (HRF) is a nonpartisan, international human rights advocacy organization based in New York, Washington, and Los Angeles. It has worked for almost 40 years with activists and attorneys to support and protect these rights through American leadership pathways. HRF has a ten-part plan entitled Walking the Talk: 2021 Blueprints for a Human Rights-Centered U.S, Foreign Policy, which provides blueprints for policymakers to uphold HRF’s recommendations.
 HRF Nonpartisan Campaigns
HRF Nonpartisan Campaigns
In advocacy of asylum seekers, HRF believes that holding the US government and its judiciary, in particular, accountable to both justice and reform when they “fail to respect human rights and the rule of law” is crucial. HRF shows its detailed plan for advocacy of asylum policy support and change in Chapter 3. Upholding Refugee Protection and Asylum at Home, the third section of the HRF 2021 policy blueprints.
In support of upholding refugee and asylum protections, HRF desires an automated tool that will allow immigration attorneys and representatives to contribute to collecting data on judicial asylum decisions and predict the likelihood a judge will render a particular decision based on past judgments. HRF would also like this tool to be able to showcase underlying patterns in the data. Current tools available to asylum seeker advocates have outdated information regarding non-sitting judges, have conflicting or missing data within the website, or are generally not user friendly.
During discussions with stakeholders and through diving into the project itself, I have initial concerns. While HRF is nonpartisan and advocacy-based, the open-source nature of the code makes this project vulnerable to being used by partisan organizations to advocate for the removal of opposite party-appointed judges. Use by third parties is not something that can be controlled or even qualified. However, it must be named as a possibility.It is also apparent that while some technical users of the tool have the skills to interpret or analyze patterns within data, others may not. Someone should provide analysis along with the prediction and visualizations. As a Data Science team, it is questionable if we have the depth of domain knowledge to provide it or the time to acquire it during the project. Of consideration is how to incorporate something stakeholders do not ask for and may not want.
Within our domain is extracting information from the documents. On the first review of the legal documents, I have immediate concerns that we do not have enough data to meet stakeholder expectations. I wonder if there is enough to complete all of our engineering tasks listed on the project roadmap to reach a minimum viable product (MVP). The documents provided by HRF stakeholders are legal documents containing judicial decisions from appellate immigration hearings. To gain insights into the stakeholder requests, we also need access to the lower immigration courts. Also of great concern is the small number of PDFs provided. For more accurate aggregate analysis and the use of machine learning models, we need large amounts of data. We have a corpus of only 1,500 documents representing an entire judicial body.
At the beginning of the project, there are more questions than answers.
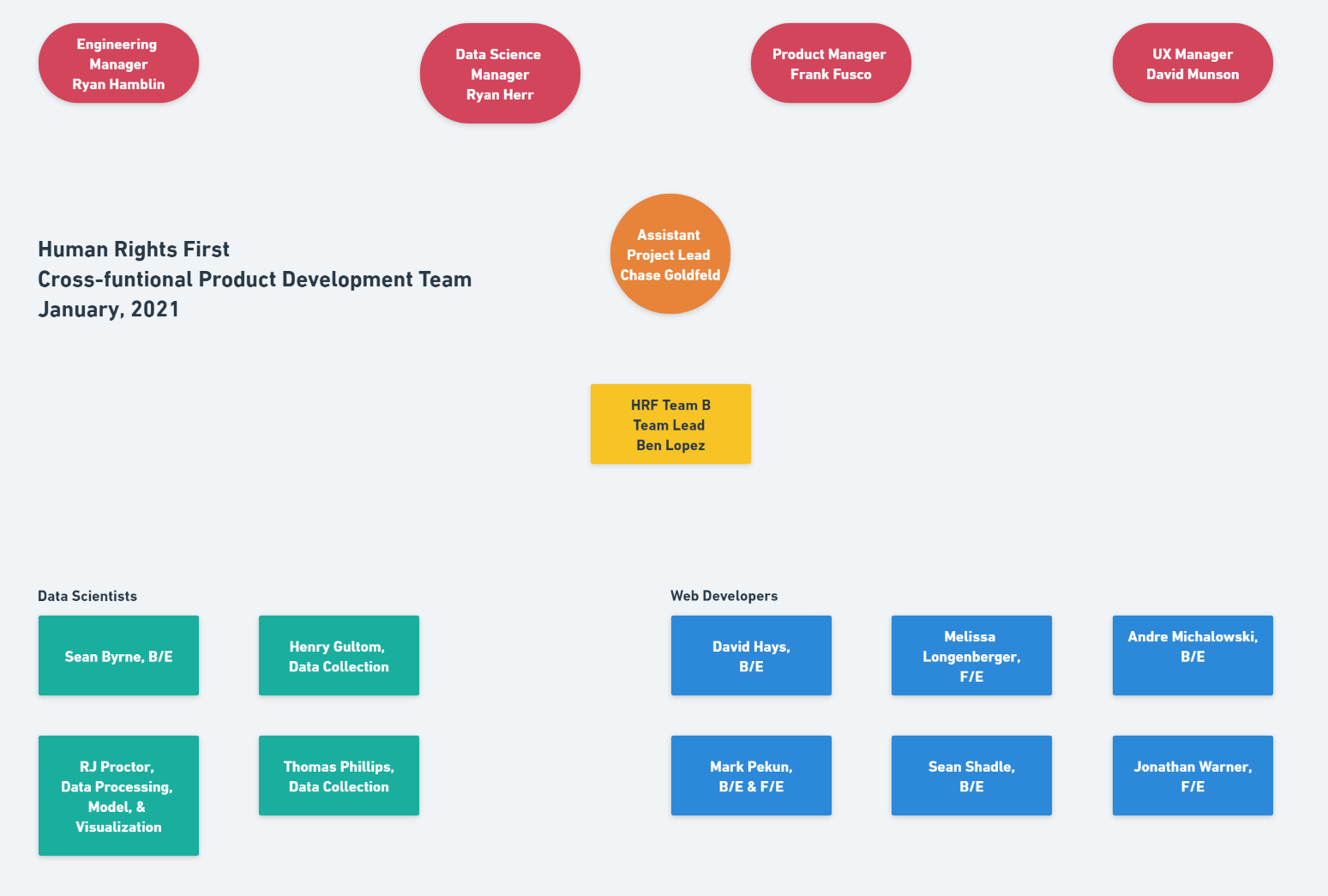 Our Team
Our Team
In the cross-functional product development team environment, the planning sprint is the most challenging and consequential in the agile domain. How a team creates and iterates planning structures makes significant changes to their work environment. In my experience during this project, collaborative planning in iterative cycles leads to compounding momentum. This momentum cycle allows our team to handle each blocker we face with greater efficiency, planned and unplanned. Taking the time to organize, research, discuss and align initially and then repeat these steps iteratively as we receive new or conflicting information is essential to our Team’s ability to create functional goals that meet stakeholder expectations.
With so many concerns, it becomes a challenge for many of my teammates to move forward on the project. Immediately recognizing the importance of coalescing as a team, I take the initiative to lead and facilitate the Data Scientists on our cross-development team in partnership with Andre Michalowski. He does the same with the Web Developers. We work under the direct leadership of Ben Lopez, our Team Lead. With the additional oversight layers, our team can remove barriers for all teammates by giving targeted support. No one is left out, behind, or succumbs to frustration because all are supported individually by leadership, the whole team, and their specialist team.
In support of my Data Science (DS) team and to lower the barrier to entry created by a lack of transfer of information from previous builds on this project, I complete a workflow document with general DS engineering tasks associated with solving our business problem as a talking point for discussions around how to meet stakeholder needs. The DS team flushes out the document together and formulates a beginning workflow. I collect information from teammates on blockers and questions for stakeholders, resolving issues I can and communicating the rest to Andre and Ben. Our team breaks the business problem down into engineering tasks; individuals claim ownership for each, and we attack the situation in these manageable chunks…momentum begins.
Our Week One Workflow Document
As I delve deeper into my specific tasks, create visualizations to represent
the prediction and patterns in the underlying data, I have a conversation
with the Data Scientist on the team managing our database, Sean Byrne.
After examination of the AWS PostgresSQL database we inherited from the
previous team, he concludes, not only is there no persistent data, but no
schema as well. We quickly realize that, like many noble houses, our
inheritance is in name only.
As a team, we decide to take some time to thoroughly examine each section of the repository (bank of code) associated with our tasks. We find that our roadmap to MVP does not align with the repository’s (repo) current state. We then revisit our workflow planning documents and strategize how to accomplish this feat within our project’s time constraints (four weeks - we are in week two, not having been given access to the repo and database until now).
During our one discussion of our discoveries, one of my teammates, Tomas Phillips, asks a thoughtful question regarding the last team, “What did they do all four weeks?” His is not a question of disrespect or belittlement; it is genuine concern regarding a lack of understanding of what blockers they faced that we aren’t seeing. My first response is simplistic; we don’t have four weeks to work on writing code. The first week is planning, and the last week we can bug fix and document, leaving two weeks to explore, build, and revise code.
Wanting to provide Tomas and the rest of the team with a more in-depth answer to his question, I look at the last team’s workflow. I see reassurance that we can accomplish the repo’s realignment to the roadmap with a slight adjustment to our workflow. Because the previous team works simultaneously on the same engineering task, they have slow overall progress, never meeting MVP. At the beginning of our planning discussions, I propose our team works asynchronously, supporting one another. After seeing the challenge the previous team faces in producing viable results, I am reaffirmed in this choice by our team.
Through this exercise, I also recognize the consequence of having a non or partially functioning scraper - no data for the database, model prediction, or visualizations. I take all of this information back to the team and propose that we make an additional change in the workflow by having two people working on data mining. Henry Gultom, who volunteers in the previous meeting to own the model as part of our alignment workflow, demonstrates his flexibility and commitment to the team by volunteering to jump over to the scraper and focus on keyword extraction.
Our Week Two Workflow Document - A Clearer Path Forward
Because of my team’s willingness to ask an honest, thoughtful question, dedication to digging deeper and removing blockers, and responsiveness when called to adjust, we gain traction in meeting stakeholder expectations where other teams stall.
My technical contributions to the project present their challenges, which
translate to fun to a Data Scientist. Essentially, my task is to classify
text and represent it in a meaningful way to a non-technical audience.
This includes supervised and unsupervised machine learning techniques to
produce a prediction and a descriptive statistical analysis based on
classification patterns. To do this, I develop processing methods for text
data, a classification model, and visualizations.
There are many different text mining approaches: data mining, machine learning, information retrieval, and knowledge management. Each seeks to extract, identify and use information from extensive collections of textual data.
Text classification is a learning process of text mining. This use case involves preprocessing the data, weighting both documents and terms, then using a classification algorithm combined with a clustering algorithm to identify similarities between documents as patterns.
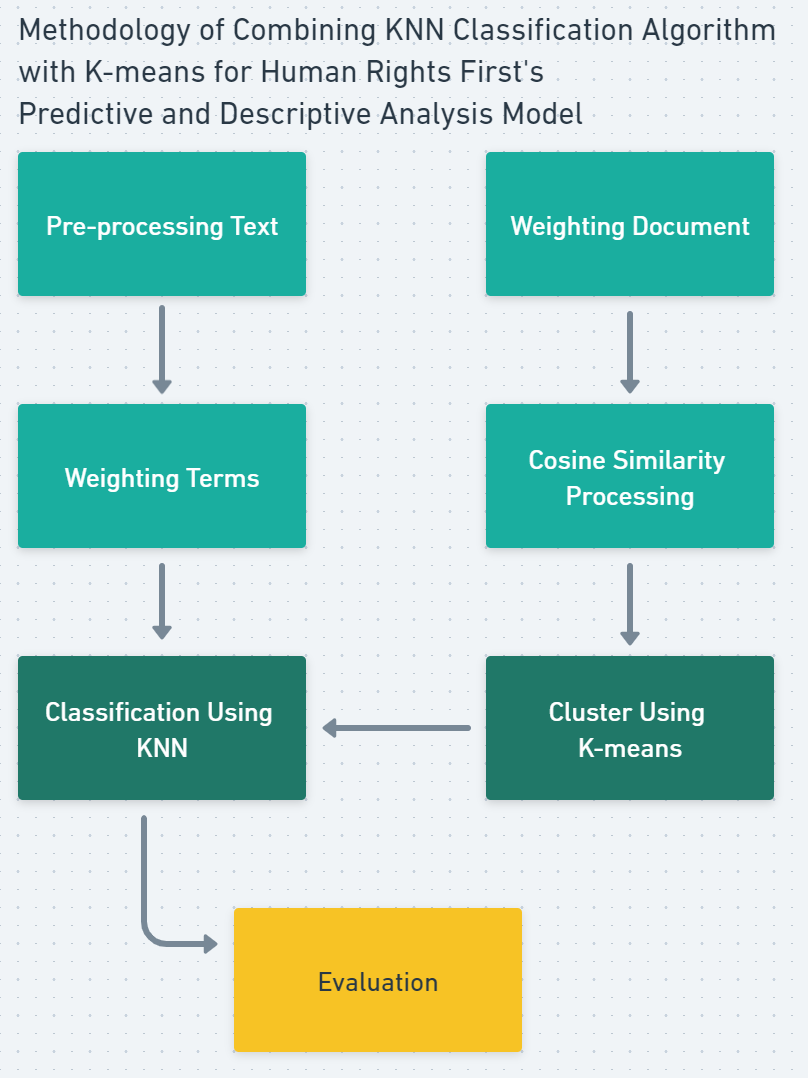 Model Methodology
Model Methodology
One of the considerations of sourcing data from users of a website is duplicate records. From a Data Science perspective, duplicate records have the potential to skew results considerably. I use SQL to directly query the database for “DISTINCT” or unique data before beginning the pre-processing stage.
The purpose of pre-processing text is to transform the text into a more digestible form for the model. Extraneous or common words like “a,” “an,” and “the” add no learning value to the model. Nor does punctuation, capitalization, HTML Code, URL links, or even variants of a word. These add up, creating noise and ambiguity while training a model.
Use of a Natural Language Processing (NLP) pre-trained model, Spacy, to case fold, tokenize, filter, and lemmatize the data allows me to search through the text to create a unique keywords list ranked the frequency they appear in all documents.
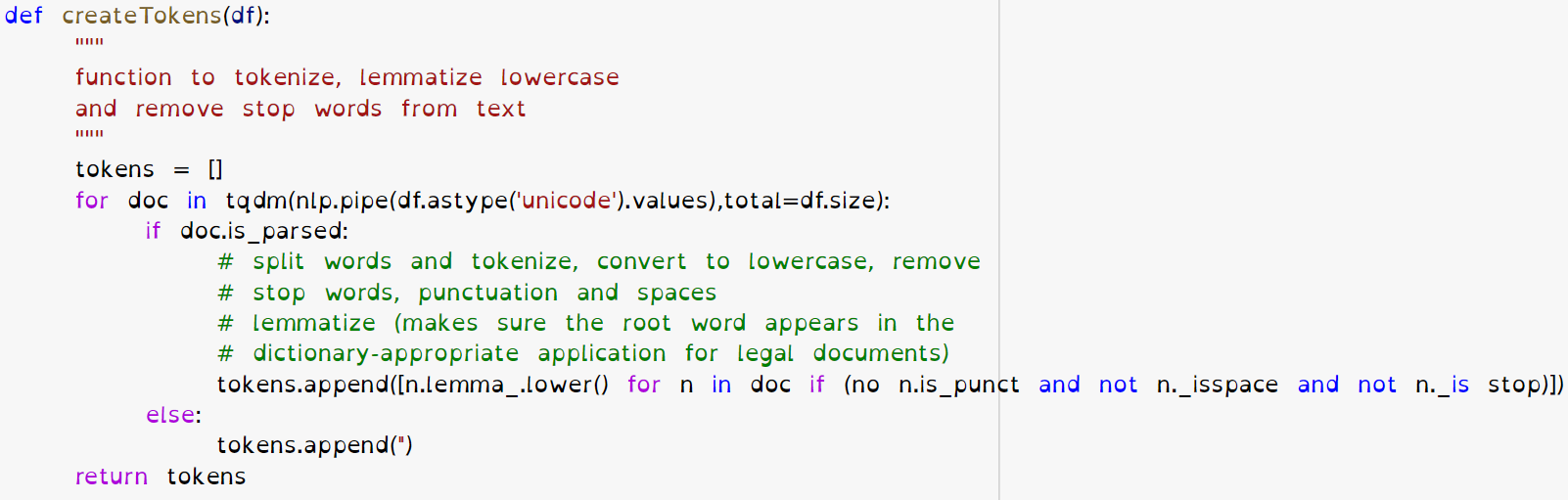 Function Using NLP to Create Tokens and Pre-Process Text Data
Function Using NLP to Create Tokens and Pre-Process Text Data
Term Frequency – Inverse Document Frequency (TF-IDF) feature weighting is a robust and straightforward method. The Term Frequency (TF) method weights terms based on the frequency the words appear in a single document. The higher the TF value of a word in a document, the higher its effect on the document. The Inverse Document Frequency (IDF) is a weighting method based on the number of words throughout all the documents in a corpus. In this use case, TD-IDF is a preprocessing dependency for Cosine similarity and clustering, which support greater efficiencies in the K-Nearest Neighbors (KNN) classification model.
The KNN algorithm is a supervised learning model, meaning it has labeled input values. The strength of the KNN model comes from its assumption that similar things exist near one another. KNN uses Euclidean distance (straight-line distance) to calculate the distance between a query example and the current data example. Due to the numbers of calculations taken between samples (test and all of the training samples), traditional KNN has great calculation complexity and can be less efficient with larger datasets. By combining KNN samples, we account for scalability because the KNN samples have the largest similarities with the clustering technique to overcome calculation complexity.
Traditional KNN text classifiers have several limitations:
- High calculation complexity to find the KNN samples - all the training samples must be calculated
- Dependence on training set - the classifier is generated only with the training samples and does not use any additional data
- No weight difference between samples - doesn’t match actual phenomenon where the samples commonly have an uneven distribution
By combining KNN with K-means, the expected outcome is a reduction in the
complex calculation of the training set after determining term weighting
to describe document importance in preprocessing.
We discover over 75% of the documents provided by stakeholders and scraped
by previous teams are not asylum cases during the production process. We
add a filter to the scraper, so these cases do not enter or corpus,
drastically reducing the number of documents we have to gain insights.
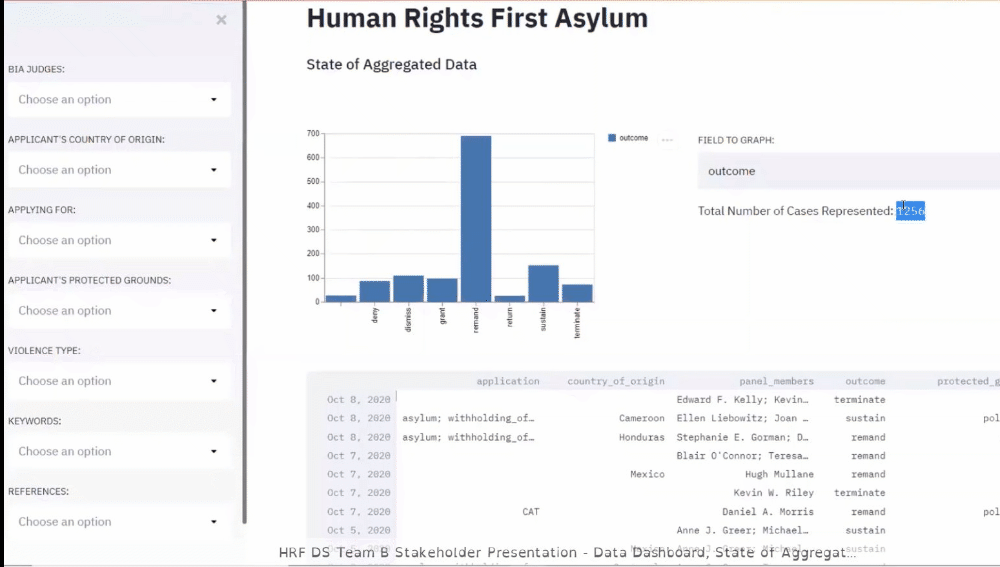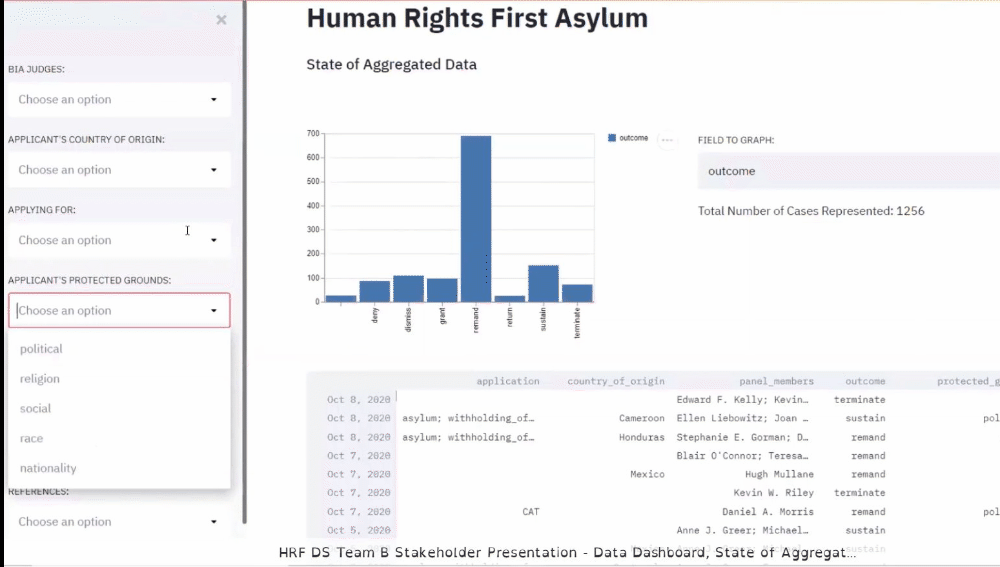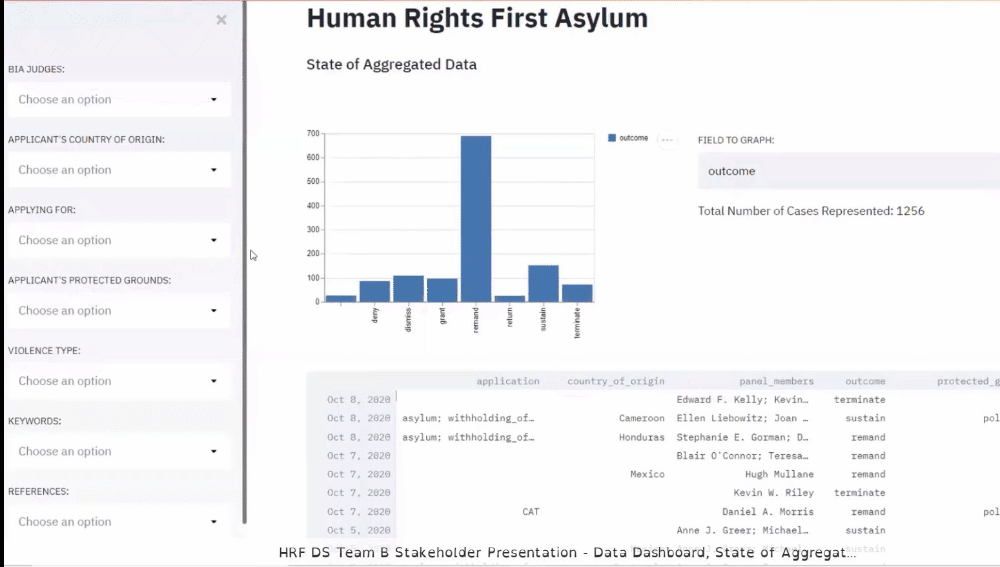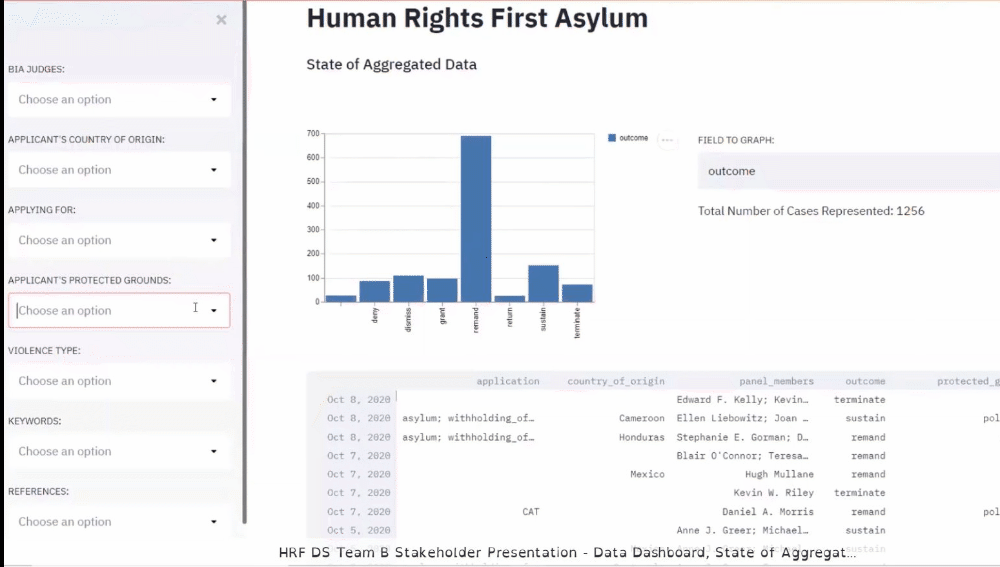 Presenting Stakeholder with the State of the Corpus
Presenting Stakeholder with the State of the Corpus
Moving forward with this project, I suggest the next team continue to explore this model, possibly seeing if you can achieve greater efficiencies using Linear Discriminant Analysis (LDA) instead of KNN and K-Means. Once there is access to a significant number of asylum documents, I suggest considering a multi-label text classification model using Keras or Convolutional Neural Network (CNN) using Tensor Flow. I also encourage the entire team to deepen their legal domain knowledge, specifically in the area of immigration law, legal documentation, and court systems.
A key aspect missing from our entire planning structure is the Alien Number. With the AN found on every immigration document, all cases relating to a single asylum seeker can be grouped. Grouping allows insights gained from tracking an individual’s progress through the entire immigration court system and comparing their experience to outcomes of those from similar circumstances. However, the AN is a confidential number similar to the social security number. The AN is treated with the same security precautions (shown only under Administrator user privileges and in hashed format under other users).
Reflecting on the journey…
Through interactions with stakeholders, I realize that stakeholder expectations can expand rapidly, sometimes even beyond our opportunity as engineers to understand the business problem and find solutions. While asking questions to clarify the business problem, our conversations would sometimes move well beyond our current project’s scope. Learning how to navigate discussions with all stakeholders to garner the information for my Data Science team needed to complete their production tasks while listening for explicit and implied asks directly from stakeholders, then asking for clarification on the implied asks, is the essential skill I acquired during this experience. Practicing this newly acquired skill is my priority.